
La Data Visualisation est entrée dans une nouvelle ère, celle de l’approche exploratoire du BIG DATA. En effet, disposer de bases de données n’est plus le problème principal puisque depuis une dizaine d’années les entreprises ont développé les moyens nécessaires pour collecter des data brutes avec des volumes de données plus importants que jamais.
L’enjeu aujourd’hui est d’explorer ces données pour y trouver des indicateurs-clés nouveaux – ceux qui sont encore cachés jusque-ici. Mais comment notre cerveau parvient-il à assimiler autant d’informations, et comment lui simplifier la tâche ?
L’enjeu exploratoire autour de la Data Visualisation
A une époque très lointaine – il y a une vingtaine d’années - lorsque les gens se posaient des questions ils s’efforçaient d’y répondre en appliquant une méthode. Ils devaient tout d’abord identifier les données brutes qui étaient susceptibles de leur apporter des éléments de réponse, puis ils devaient trouver un moyen de collecter ces données, et enfin ils devaient mettre en place une méthode d’analyse pour exploiter au mieux les données qu’ils étaient parvenus à collecter.
Ainsi, en raison de la non-disponibilité immédiate de la data, chaque question nouvelle qu’ils se posaient impliquait d’inventer une nouvelle méthode pour y répondre.
Aujourd’hui, époque de profusion des données, l’enjeu analytique autour de la data demeure mais est animé par des contraintes nouvelles : le problème n’est plus de pouvoir collecter les bonnes données, il est de parvenir à explorer des volumes de données plus importants que jamais pour représenter visuellement la connaissance client.
Si conduire une étude de marché fait toujours sens pour connaitre la perception de mes produits, il y a également sur le Web un immense volume de données, immédiatement disponible, qui reflète également cette perception. Seulement voilà : comment exploiter cette montagne de données Internet pour en extraire des informations utiles ? La réponse n’est pas seulement liée à des outils analytiques, car elle est avant tout liée aux capacités analytiques de notre cerveau à établir une zone de visualisation.

La Data Visualisation est plus efficace que la représentation symbolique
Lorsque notre cerveau doit explorer un grand volume de data, les représentations visuelles (infographies, graphes, cartes interactives, cartographies, courbes...) – ou Data Visualisations - s’avèrent bien plus efficaces que les représentations symboliques – ou tableaux de données.
En effet, face à un tableau de données chiffrées, le temps nécessaire à notre cerveau pour isoler la réponse à une question est proportionnel au nombre d’entrées de ce tableau. Ainsi, plus un tableau est complexe, moins son interprétation est intuitive.
A contrario, la visualisation graphique de données permet d’identifier plus rapidement des éléments remarquables et les corrélations qui les lient. Ainsi, la représentation visuelle des données permet non seulement de répondre à des questions plus rapidement mais également de se poser des questions nouvelles sur la base de corrélations que l’on n’envisageait pas initialement mais qui pourtant « sautent aux yeux ».
Représentation graphique : 1, représentation symbolique : 0.
Pourquoi est-ce que la représentation visuelle nous semble si efficace ? L’explication est en fait cognitive. La psychologue américaine Anne Treisman a découvert en 1985 que devant une représentation graphique, le système perceptif humain est capable de faire des traitements instantanés et sans efforts. Mieux, quel que soit le nombre d’éléments présentés dans le graphique, le cerveau peut répondre de manière très fiable à des questions liées au informations exploitables, même si le graphique n’est affiché qu’une fraction de seconde.

Anne Treisman explique cette prouesse par la capacité de perception pré-attentive de notre cerveau qui nous permet d’identifier un grand nombre de caractéristiques visuelles instantanément (couleur, orientation, lignes, …). A l’inverse, et toujours à cause de cette perception pré-attentive, si nous ne sommes pas exposés à une représentation visuelle adéquate, le temps de traitement nécessaire au cerveau pour « comprendre » ce qu’il « voit » devient proportionnel au nombre d’objets à étudier. On mettra donc toujours plus de temps à comprendre des tableaux de bord de données qu’une Data Visualisation permettant de fluidifier les processus d'aide à la décision.
Représentation graphique : 2, représentation symbolique : 0.
Meilleur buteur : la perception pré-attentive.
Data Visualisation : le modèle de variables visuelles
Le choix des variables visuelles est donc crucial pour utiliser les représentations qui libéreront tout le potentiel de notre cerveau. Heureusement les recherches en psychologies cognitives ont largement exploré la pertinence des différentes variables visuelles selon la nature des caractéristiques à visualiser. Jacques Bertin, notamment, a présenté un modèle de variables visuelles définies selon des critères multiples afin de constituer des « primitives graphiques » efficaces :
-
la position,
-
la longueur,
-
l’angle,
-
la pente,
-
la surface,
-
la forme
-
et la couleur (divisée elle-même en intensité, saturation et teinte)
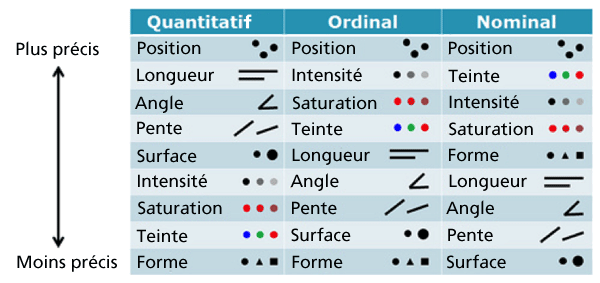
Système de variables visuelles - Jacques Bertin
Imaginons un tableau de données à deux entrées : un millier de références produits associées à leur ventes constatées sur l’année et le taux de marge moyen par produit. Selon le système de Bertin, la représentation visuelle la plus efficace sera de traiter l’aspect quantitatif en utilisant la position, donc de positionner chaque produit suivant deux axes – le chiffre d’affaire et le taux de marge de chacun.
Si l’on souhaite ajouter une troisième dimension, comme les produits les plus rentables, ont utilisera une dimension ordinale, comme une intensité de couleur pour distinguer les produits à forte marge, de ceux qui ont une marge dans la moyenne et ceux qui ont une marge en-dessous de la moyenne.
Allons plus loin. Nous pourrions également souhaiter introduire une quatrième dimension : les familles ou catégories de produits. Toujours avec le système de Bertin, nous appliquerions alors des couleurs différentes à cette dimension nominale, avec une couleur spécifique à chaque grande famille de produits.
Le système de variables visuelles de Jacques Bertin permet donc d’introduire plusieurs niveaux d’informations à des représentations graphiques qui sont limitées à deux dimensions.
Représentation graphique : 3, représentation symbolique : 0.
Meilleur tacticien : Jacques Bertin
Data Visualisation : la nécessité de l'interaction
La représentation graphique des données permet donc de comprendre plus rapidement et plus efficacement ces données, pour en tirer des conclusions actionnables et agir en conséquence. A ce propos James J. Gibson concluait dès 1950 que nous devons percevoir pour agir et agir pour percevoir, introduisant ainsi l’importance de l’interaction avec les informations graphiques.
C’est physiologique : pour percevoir un objet, nous bougeons notre tête autour de lui et si l’objet est trop petit nous bougeons directement l’objet. Le cerveau humain a besoin de « voir » un objet sous plusieurs angles afin de mieux le comprendre. Dans cette logique, si l’on associe des interactions à des représentations graphiques on augmente tout simplement le volume d’informations utiles que notre cerveau en retire. A contrario, si l’œil reste immobile, l’image rétinienne disparaît et le volume d’information issu de l’image s’arrête.

L’interaction avec les représentations visuelles sont d’autant plus nécessaires que notre mémoire à court terme est un outil en réalité très limité. L’être humain dispose de plusieurs types de mémoire, dont la mémoire de travail – la mémoire à court terme- que nous sollicitons lorsque nous réfléchissons.
En 1956 George A. Miller a établi que nous ne pouvons mémoriser que sept items. Lorsque nous réfléchissons nous échafaudons un plan des réponses que nous attendons, chaque réponse mobilisant un item. Or, ce plan est stocké dans notre mémoire de travail et la multiplication d’item redéfinit le plan que nous avons échafaudé. Vu sous cet angle, « Etre perdu » face à un sujet complexe prend un sens littéral puisque nous sommes en effet perdus dans le plan que nous avons échafaudé : chaque nouvelle réponse attendue ajoute un item à notre mémoire de travail qui ne peut en contenir que sept, ce qui redéfinit notre plan jusqu’au point où ne savons plus où nous en sommes ni comment nous en sommes arrivés là.
En revanche, l’interaction avec une représentation des données graphique ne mobilise pas d’item. Nous pouvons alors échafauder des plans bien plus complexes et explorer des alternatives beaucoup plus nombreuses. Couplé à nos capacités pré-attentives, les interactions permettent alors de modifier des paramètres de réflexions tout en lisant les résultats à grande vitesse sans saturer notre mémoire à court terme. On appelle cela une boucle de rétroaction, et c’est une arme analytique redoutable.
En effet, ces suites de boucles itératives nous permettent de visualiser l'information rapidement sur de très vastes espaces de données pour y trouver – parfois de manière fortuite – des informations que l’on ne cherchait pas mais qui s’avèrent utiles. Autrement dit, le tamdem interaction + capacité pré-attentive nous permet de révéler l’information cachée.
Représentation graphique : 4, représentation symbolique : 0
Meilleur attaquant : la boucle de rétroaction.
Que nous apporte cette plongée dans le fonctionnement de notre cerveau lorsqu’il est exposé à des données complexes ?
Elle nous permet tout d’abord de comprendre que la représentation graphique décuple notre potentiel dans le traitement des données.
Encadré par des variables visuelles efficaces, les représentations visuelles délivrent un volume d’information plus massif et plus expressif.
Cependant notre cerveau reste limité par la capacité de notre mémoire de travail. L’interaction avec la représentation graphique permet de dépasser cette limite en préservant les capacités de notre mémoire à court terme tout en initiant des boucles de rétroactions qui nous permettent de révéler intuitivement des informations cachées.
Le reporting selon Reeport
Au siècle de la transformation digitale les entreprises se retrouvent face à d'important volumes de données occultant les indicateurs de performance qui permettent aux organisations de prendre de meilleures décisions pour le monitoring de l'activité.
Dans cet océan de données les entreprises doivent redoublés d'efforts pour analyser les données pertinentes dans leurs écosystèmes multi-sources et multi-formats. Cependant ces étapes sont complexes et demandent un travail de préparation des données pour ressortir les KPIs qui guideront vos décisions stratégiques.
Reeport est une solution SaaS entièrement automatisée qui vous accompagne sur toutes les étapes de votre reporting pour fluidifier l'exploitation des données en regroupant les indicateurs-clés de performance dans un univers centralisé pour fluidifier la visualisation et le partage de ces KPIs à l'ensemble de vos collaborateurs et des décideurs.
En ce sens Reeport DataViz est une solution de web intelligence qui vous permet d'optimiser la visualisation des données de façon interactives en créant des dashboard (tableau de bord) personnalisés dans une interface de visualisation simple, interactive et collaborative pour ainsi partager les actions décisionnelles moteurs de votre activité à l'ensemble de vos équipes.
Pour en savoir plus :
- La Data Visualisation : histoire et évolution
- La fille de fermier qui a révolutionné les chronographies
- Quel type de Data Visualisation pour quel type de données ?
- Data Visualisation : il a inventé l'eau gazeuse et la frise chronologique
- Data Visualisation : il a pris la Bastille et inventé les histogrammes
- Comment un constructeur de ponts a fait avancer la Data Visualisation
- Data Visualisation : Une infirmière a inventé vos diagrammes circulaires


COMMENTAIRES