
La Data Visualisation exploite des spécificités de notre cerveau afin de nous permettre de comprendre plus vite, mieux et plus facilement des données pour prendre les décisions appropriées. Cependant, comme tout outil, la Data Visualisation présente des variantes qui sont chacune adaptées à un usage plus spécifique. Ce petit guide synthétise des principes simples pour comprendre quel type de Data Visualisation est à privilégier en fonction des données qu’il représente et de l’usage que l’on souhaite en faire.
La Data Visualisation oui, mais pas n'importe comment.
En utilisant des Data Visualisations, nous gagnons avant tout du temps. Par exemple une Data Visualisation du contenu de cet article révèle instantanément que c’est principalement le nombre de dimensions que l’on applique aux données qui détermine le type de Data Visualisation à appliquer.

Data Visualisation des données monodimensionnelles
Lorsque l’on souhaite représenter la variation d’une valeur sur une période, on pense invariablement à une ligne de temps, qui est effectivement une Data Visualisation monodimensionnelle parfaitement appropriée.
Très accessible, ce type de visualisation permet de mettre en évidence les fluctuations d’une donnée sur un intervalle défini et d’en dégager intuitivement une tendance.
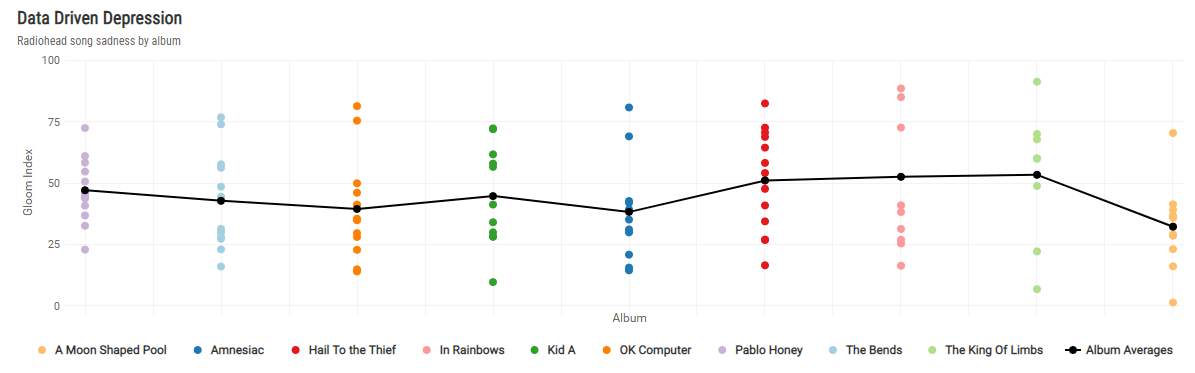
Variation de l’indice de tristesse des albums de Radiohead entre 1993 et 2016
Si ce type de Data Visualisation est très populaire c’est qu’il permet de représenter facilement les variations d’une valeur au sein d’une séquence. En revanche, il ne permet pas de traiter facilement les liens entre les sous-séquences, c’est-à-dire entre les éléments qui donnent à la valeur sa variation.
Imaginons que nous nous intéressions à l’évolution des dialogues entre les épisodes IV, V et VI de StarWars. Une ligne de temps nous permettrait de visualiser les variations du nombre de mots, ou du nombre de dialogues. Cependant la ligne de temps ne permettrait pas de comprendre les liens qui existent entre les sous-séquences, c’est-à-dire les dialogues entre les personnages.
Pour visualiser ces sous-séquences à l’intérieur d’une séquence, nous pouvons recourir aux digrammes en arc.

Digramme en arc des dialogues entre les différents personnages des épisodes 4,5 et 6 de StarWars.
Dans cet exemple on constate que le jeune Luke est de moins en moins bavard au fil des épisodes même s’il est le personnage qui a le plus grand temps de parole. Han Solo, à contrario, reste fidèle à lui-même entre les trois épisodes et se révèle être l’interlocuteur principal de Luke. Le diagramme en arc révèle donc des liens entre les sous-séquences qui expliquent les variations de la séquence en elle-même.
Appliqués à une dimension temporelle, les diagrammes en arc permettent de comprendre la structure d’une variation, c’est-à-dire son schéma.
La Data Visualisation des données multidimensionnelles
La plupart des données que nous souhaitons analyser présentent cependant plus d’une seule dimension et doivent donc être traitées par des Data Visualisations plus adaptées.
Héritage direct de la cartographie, les données à deux dimensions nous ont donné l’habitude des diagrammes cartésiens, c’est-à-dire des représentations où chaque point est localisé par deux coordonnées. Un axe X, un axe Y, et nous comprenons instantanément que chaque point, courbe ou zone est directement défini par les valeurs qu’il prend dans ces deux dimensions.
Les diagrammes cartésiens à point – ou diagrammes en semis – présentent l’avantage de révéler intuitivement des corrélations entre les dimensions étudiées, ainsi que les maxima, minima et moyennes qui se dégagent de l’ensemble des données.
Cependant, au-delà de deux dimensions les digrammes en semis présentent une limite de lisibilité. On peut toujours traduire une troisième dimension en ajoutant une variable visuelle comme la taille, la couleur, la teinte ou la forme des points, mais on perdra vraisemblablement en efficacité : la représentation sera moins lisible et l’effort de compréhension plus important.
Au-delà de deux dimensions, il est donc recommandé d’opter pour d’autres types de Data Visualisations.

Pour analyser plusieurs dimensions, on peut tout d’abord comparer différentes vues en diagrammes en semis. Imaginons par exemple que l’on souhaite analyser des données à travers 4 dimensions. On commencera par produire un diagramme en semi avec les deux dimensions les plus importantes. Cette vue nous permettra d’isoler certaines données – les points remarquables. On appliquera alors à ces points – et pas aux autres- les 2 autres dimensions dans un nouveau diagramme en semi. Cette méthode, exploratoire, permet d’observer les principales données (les points remarquables) sous différentes dimensions (les axes qu’on y applique) afin d’en déduire des corrélations ou l’absence de corrélation.
Bien entendu, pour analyser des données multidimensionnelles il existe des Data Visualisations qui exigent moins de démarches exploratoires.
Les coordonnées parallèles permettent de représenter sur une même vue différentes dimensions à l’aide d’axes verticaux. Les lignes horizontales y représentent les différents éléments que l’on souhaite comparer dans ces dimensions. Chaque élément va donc couper successivement les axes en traçant un chemin qui lui est spécifique.
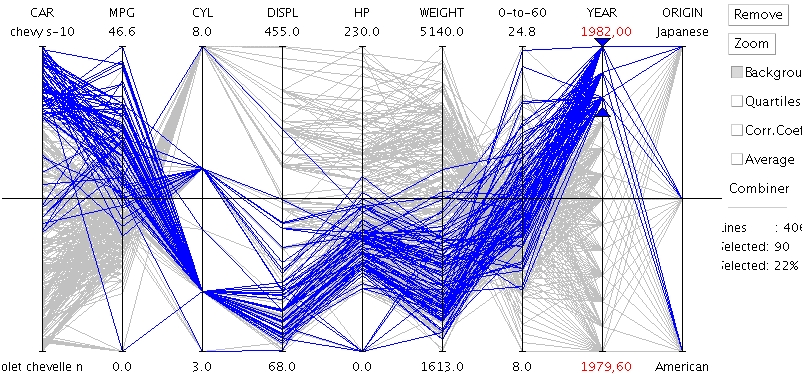
Exemple de coordonnées parallèles
Dans cet exemple, des coordonnées parallèles comparent plusieurs modèles de voitures (ce sont les lignes) à travers de multiples dimensions (ce sont les axes verticaux). On y découvre par exemple que plus une voiture est récente moins elle pèse lourd et moins elle a de cylindres.
Très précis, ce type de représentation nécessite néanmoins un temps d’apprentissage. On lui préférera donc souvent une Data Visualisation moins précise mais plus intuitive comme le Treemap.
Le Treemap entre dans la famille des arbres et des hiérarchies qui nous permettent de décrire des organisations.
A ce titre un arbre généalogique est un exemple d’arbre qui représente une organisation familiale à travers des nœuds et des liens. Dans le cas du Treemap, la racine de l’arbre (l’origine de la hiérarchie) est l’écran de visualisation. Les éléments issus de cette racine (les enfants) sont des rectangles contenus dans cet écran.
La particularité du Treemap est donc qu’il présente une vue hiérarchisée qui traduit simplement les relations complexes qui peuvent lier les données.
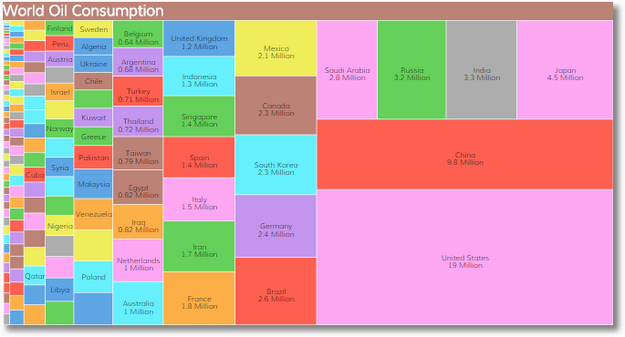 exemple de Treemap sur la répartition mondiale de la consommation de pétrole
exemple de Treemap sur la répartition mondiale de la consommation de pétrole
En conclusion de ce petit guide, nous sommes bien entendu tentés d’établir un lien entre Data Visualisation et diffusion de l’information.
La visualisation d’information est une méthode efficace pour permettre au plus grand nombre de comprendre des données, mais surtout de voir des informations dans leur contexte. Si l’enjeu au niveau des entreprises est évident, nous pouvons également donner à la Data Visualisation une portée plus sociétale.
En effet, il semblerait qu’en introduisant un mode de lecture ludique et intuitif d'informations complexes, les Data Visualisation déplacent peu à peu le niveau de connaissance et de compréhension du plus grand nombre.
Pour en savoir plus :
- La Data Visualisation : histoire et évolution
- La fille de fermier qui a révolutionné les chronographies
- Comment la Data Visualisation décuple les capacités de notre cerveau
- Data Visualisation : il a inventé l'eau gazeuse et la frise chronologique
- Data Visualisation : il a pris la Bastille et inventé les histogrammes
- Comment un constructeur de ponts a fait avancer la Data Visualisation
- Data Visualisation : Une infirmière a inventé vos diagrammes circulaires


COMMENTAIRES